Deduplizierung an der Quelle
Während der Backup-Erstellung zu einem deduplizierenden Depot berechnet der Acronis Backup Agent für jeden Datenblock einen so genannten Fingerabdruck. Ein solcher Fingerabdruck wird auch als Hash-Wert bezeichnet.
Bevor ein Datenblock zum Depot übertragen wird, fragt der Agent die Deduplizierungsdatenbank ab, um zu bestimmen, ob der Hash-Wert dieses Blocks dem eines bereits gespeicherten Blocks entspricht. Trifft dies zu, dann überträgt der Agent nur den Hash-Wert, wenn nicht, dann wird der Block selbst übertragen. Der Storage Node speichert die empfangenen Datenblöcke in einer temporären Datei.
Einige Daten, etwa verschlüsselte Dateien oder Laufwerksdatenblöcke mit nicht standardkonformer Größe, können nicht dedupliziert werden. Solche Daten werden vom Agenten immer ohne Berechnung ihrer Hash-Werte zum Depot übertragen. Mehr Informationen über Beschränkungen bei der Deduplizierung finden Sie unter Deduplizierungsbeschränkungen.
Sobald der Backup-Prozess abgeschlossen wurde, sind im Depot das resultierende Backup sowie die temporäre Datei mit den einmaligen Datenblöcken enthalten. Die temporäre Datei wird dann in der nächsten Phase verarbeitet. Das Backup (eine tib-Datei) enthält Hash-Werte zusammen mit Daten, die nicht dedupliziert werden können. Eine weitere Verarbeitung dieses Backups ist nicht notwendig. Sie können ohne Weiteres Daten aus diesem wiederherstellen.
Deduplizierung am Ziel
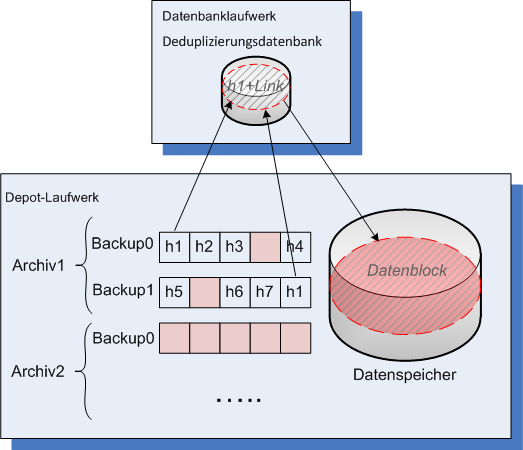
Nachdem ein Backup zu einem deduplizierenden Depot abgeschlossen wurde, führt der Storage Node eine Indizierungsaktivität aus. Durch diese Aktivität werden die Daten in dem Depot folgendermaßen dedupliziert:
Als Ergebnis enthält der Datenspeicher eine bestimmte Anzahl an einmaligen Datenblöcken. Von den Backups gibt es einen oder mehrere Verweise auf jeden Block. Die Verweise sind in der Deduplizierungsdatenbank enthalten. Die Backups selbst verbleiben unberührt. Sie enthalten Hash-Werte sowie Daten, die nicht dedupliziert werden können.
Das nachfolgende Diagramm illustriert das Prinzip der Deduplizierung am Ziel.
Eine Indizierungsaktivität kann eine beträchtliche Zeit zur Fertigstellung benötigen. Sie können das Stadium dieser Aktivität auf dem Management Server einsehen, wenn Sie den entsprechenden Storage Node auswählen und auf Details anzeigen klicken. Sie können diese Aktivität in dem Fenster auch manuell starten oder stoppen.
Falls Sie eine große Menge von einmaligen Daten per Backup sichern, kann die Indizierungsaktivität durch zu wenig Arbeitsspeicher (RAM) auf dem Storage Node fehlschlagen. Die Ausführung der Backups wird aber fortgesetzt. Sie können dem Storage Node mehr RAM hinzufügen oder nicht mehr benötigte Backups löschen und dann eine Verdichtungsaktion ausführen. Die Indizierung wird nach dem nächsten Backup erneut ausgeführt.
Verdichten
Wurden ein oder mehrere Backups bzw. Archive vom Depot gelöscht (entweder manuell oder durch Bereinigung), so kann der Datenspeicher Datenblöcke enthalten, auf die sich keine Archive mehr beziehen. Solche Blöcke werden dann durch einen Verdichtungstask gelöscht, bei dem es sich um einen geplanten, vom Storage Node ausgeführten Task handelt.
Als Standardvorgabe läuft der Verdichtungstask jeweils sonntags in der Nacht um 03:00 Uhr. Sie können den Task neu planen, indem Sie den entsprechenden Storage Node wählen, zuerst auf Details anzeigen klicken und dann auf Verdichtungsplanung. Sie können den Task in dieser Registerlasche auch manuell starten oder stoppen.
Da das Löschen unbenutzter Datenblöcke ein ressourcenverbrauchender Prozess ist, wird der Verdichtungstask nur ausgeführt, wenn sich eine ausreichende Datenmenge angesammelt hat. Der Grenzwert wird über den Konfigurationsparameter Compacting Trigger Threshold bestimmt.