La technologie de déduplication de sauvegarde aide à réduire les coûts de stockage et l'utilisation de la bande passante du réseau en éliminant les blocs de données en double lorsque vous sauvegardez et transférez des données.
La déduplication vous aidera à:
- Réduire l'utilisation de l'espace de stockage en ne stockant que des données uniques
- Éliminer le besoin d'investir dans du matériel spécifique à la déduplication de données
- Réduire la charge réseau parce que moins de données sont transférées, ce qui laisse plus de bande passante pour vos tâches de production.
Rappelez-vous, cependant, que le stockage dédupliqué peut nécessiter plus de ressources informatiques, telles que la RAM et/ou le processeur. Dans certains cas, le stockage traditionnel non dédoublé peut être plus rentable que le stockage dédupliqué. Vous devez toujours analyser vos besoins et votre infrastructure avant de mettre en place la déduplication.
Les défis du stockage de sauvegarde
Nous vivons à l'ère du Big Data.
En 1990, le disque dur d'un ordinateur personnel faisait 10 mégaoctets. Aujourd'hui, les disques de plusieurs téraoctets sont devenus la norme. Toutes les 10 minutes, l'humanité crée autant de données qu'elle en a créé depuis l'aube de la civilisation jusqu'à l'an 2000.
Il est nécessaire de protéger et sauvegarder toutes ces données. Sinon, votre entreprise pourrait perdre de l'argent, sa réputation, du temps et toute votre entreprise pourrait même fermer ses portes.

Cependant, 75% des petites et moyennes entreprises (PME) interrogées par Acronis et IDC (International Data Corporation) admettent que leurs données ne sont pas complètement protégées. Le «poids des données» a été cité comme l'une des principales raisons.
Prenons l'exemple d'une entreprise avec 400 employés qui utilisent des ordinateurs de bureau et des ordinateurs portables. Un ordinateur portable moyen peut contenir de 50 à quelques centaines de gigaoctets de données sur son disque dur. Les PC contiennent de 20 à 150 To (téraoctets) de données. Avec un taux de compression de 2: 1, l'administrateur de sauvegarde doit fournir entre 10 et 75 To pour chaque sauvegarde complète et disposer d’encore plus d'espace disque pour les sauvegardes incrémentielles et différentielles. En fin de compte, cette société pourrait avoir besoin d'acquérir jusqu'à un pétaoctet de stockage pour les sauvegardes de PC.
Supposons que cette société investit dans du stockage coûteux pour ses sauvegardes de PC. Le défi suivant, encore plus grand, est de sauvegarder les PC sur ce stockage. Un réseau de 100 Mbit (mégabit) ne peut transférer que 10 mégaoctets de données par seconde. A ce rythme, une sauvegarde complète prendra de deux à trois semaines pour transférer 10 à 75 To de données sur un réseau 100 Mbit.
Pourtant, chaque ordinateur de bureau possède le même système d'exploitation Windows, les mêmes applications et souvent de nombreuses copies des mêmes données. Stocker et transférer les mêmes données plusieurs fois sur le même espace de stockage est une perte de temps et de ressources. Si une solution de sauvegarde transfère et stocke uniquement des données uniques, l'entreprise peut réduire sa capacité de stockage et ses besoins réseau jusqu'à 50 fois ! Grâce à la déduplication, votre entreprise peut réaliser ces économies.
Qu'est-ce que la déduplication des sauvegardes ?
La déduplication de sauvegarde minimise l'espace de stockage en détectant la répétition des données et en ne stockant les mêmes données qu'une seule fois. La déduplication réduit également la charge réseau, car les doublons de données précédemment sauvegardées ne seront même pas transférés sur le réseau vers l’espace de stockage.
Lorsque vous activez la déduplication, votre solution de sauvegarde déduplique les sauvegardes et les enregistre dans un support de stockage. Une zone de stockage où la déduplication est activée s'appelle un stockage de déduplication .
La déduplication peut fonctionner au niveau d'un fichier, d'un sous-fichier (morceaux de fichiers) ou d'un bloc et fonctionne généralement avec tous les systèmes d'exploitation pris en charge par votre solution de sauvegarde.
La déduplication produit un maximum de résultats lorsque vous créez :
- Des sauvegardes complètes de données similaires provenant de différentes sources, telles que les systèmes d'exploitation (OS), les machines virtuelles (VM) et les applications déployées à partir d'une image standard
- Des sauvegardes complètes des systèmes que vous avez précédemment sauvegardés sur le même espace de stockage de déduplication
- Des sauvegardes incrémentielles de données similaires provenant de différentes sources; par exemple, lorsque vous déployez des mises à jour du système d'exploitation sur plusieurs systèmes et exécutez une sauvegarde incrémentielle
- Des sauvegardes incrémentielles lorsque les données ne changent pas, mais que l'emplacement des données change, mais que l'emplacement des données change; par exemple, lorsque des données, telles qu'un fichier, circulent sur le réseau ou dans un système et apparaissent dans un nouvel emplacement
Comment fonctionne la déduplication de sauvegarde?
Lors de la déduplication, les données de sauvegarde sont divisées en blocs. L'unicité de chaque bloc est vérifiée par une base de données spéciale, qui vérifie toutes les sommes de contrôle des blocs stockés. Les blocs uniques sont envoyés au stockage et les doublons sont ignorés.
Par exemple, si 10 machines virtuelles sont sauvegardées dans un stockage dédupliqué et que le même bloc se retrouve dans cinq d'entre elles, une seule copie de ce bloc est envoyée et stockée.
Cet algorithme de saut des blocs dupliqués permet d'économiser de l'espace de stockage et de minimiser le trafic réseau.
Déduplication à la source
Lors de l'exécution d'une sauvegarde vers un stockage de déduplication, la solution de sauvegarde calcule une empreinte digitale ou une somme de contrôle de chaque bloc de données. Cette empreinte digitale ou somme de contrôle est souvent appelée une valeur de hachage.
Votre solution de sauvegarde peut prendre en charge des blocs de taille fixe ou variable. La déduplication de blocs de taille fixe s'est avérée inefficace - sur des blocs de petite taille, elle consomme beaucoup de RAM et de CPU ; et sur des blocs de grande taille, elle fournit un ratio de déduplication beaucoup plus faible.
La plupart des solutions de sauvegarde modernes avancées permettent une déduplication de blocs de taille variable, adaptant la taille des blocs pour maximiser le taux de déduplication, tout en réduisant l'utilisation de la RAM et du CPU.
Avant d'envoyer le bloc de données au stockage, la solution de sauvegarde interroge le système de stockage pour déterminer si la valeur de hachage du bloc y est déjà stockée. Si c'est le cas, la solution n'envoie que la valeur de hachage ; sinon, elle envoie le bloc lui-même.
Certaines données, comme les fichiers chiffrés ou les blocs de disque d'une taille non standard, ne peuvent pas être dédupliquées. Dans ces cas, la solution transférerait toujours ces données vers le stockage sans calculer les valeurs de hachage.
Déduplication à la cible
Une fois qu'une sauvegarde vers un stockage de déduplication est terminée, le système de stockage effectue la déduplication côté stockage. Habituellement, ce processus fonctionne de cette façon :
- Les blocs de données sont déplacés du fichier de sauvegarde vers un fichier spécial, la mémoire de données de déduplication, dans le stockage. Les blocs en double ne sont stockés qu’une seule fois.
- Les valeurs de hachage et les liens vers les blocs de données sont sauvegardés dans la base de données de déduplication , de sorte que les données peuvent être facilement réassemblées (réhydratées).
Par conséquent, la mémoire de données de déduplication contient un certain nombre de blocs de données uniques. Chaque bloc contient une ou plusieurs références des sauvegardes. Les références sont enregistrées dans la base de données de déduplication.
La figure ci-dessous illustre le résultat de la déduplication à la cible.
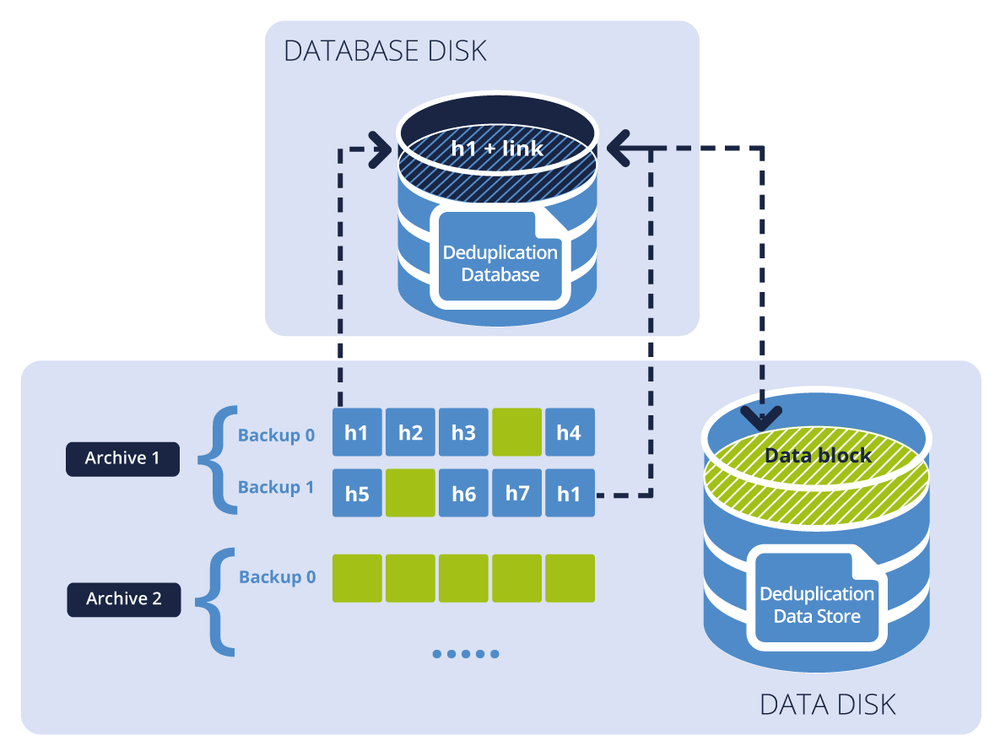
Le diagramme montre deux archives de sauvegarde. Chacune dispose d'un ensemble distinct de sauvegardes. Dans l’Archive 1, h1 à h7 - désignés par des blocs bleus - contiennent des valeurs de hachage stockées dans les fichiers de sauvegarde. Les blocs verts sont les blocs de données qui ne peuvent pas être dédupliqués. L’Archive 2 ne contient que des blocs de données (en vert) et est crypté. Par conséquent, la base de données de déduplication contient les valeurs de hachage des blocs qui peuvent être dédupliqués, et la base de données de déduplication contient des blocs de données provenant à la fois de l'Archive 1 et de l'Archive 2.
Restauration
Pendant la restauration, l'agent de la solution de sauvegarde demande les données du stockage. Le système de stockage lit les données de sauvegarde de la mémoire et si un bloc est référencé dans la mémoire de données de déduplication, le système de stockage lit les données qui s'y trouvent. Pour l’ agent, le processus de récupération est transparent et indépendant de la déduplication.
Suppression de blocs de données orphelins
Une fois qu'une ou plusieurs sauvegardes sont supprimées du stockage - manuellement ou par le biais de règles de conservation - la mémoire de données peut contenir des blocs qui ne sont plus référencés par aucune sauvegarde. Ces blocs orphelins sont alors supprimés par une tâche spéciale planifiée exécutée par le système de stockage.
Voici comment cela fonctionne. Tout d'abord, le système de stockage analyse toutes les sauvegardes du stockage et marque tous les blocs référencés comme étant utilisés (le hachage approprié est marqué comme utilisé dans la base de données de déduplication). Deuxièmement, le système de stockage supprime tous les blocs inutilisés.
Ce processus peut nécessiter des ressources système supplémentaires. C'est pourquoi cette tâche n'est généralement exécutée que lorsqu'une quantité suffisante de données s'est accumulée dans votre espace de stockage.
Compression et chiffrement
L'agent de la solution de sauvegarde compresse généralement les données sauvegardées avant de les envoyer au serveur. Les valeurs de hachage pour chaque bloc de données sont calculées avant compression. Cela signifie que si deux blocs égaux sont compressés avec des niveaux de compression différents, ils seront toujours reconnus comme des doublons.
Les sauvegardes cryptées côté source ne sont pas dédupliquées pour des raisons de sécurité.
Pour tirer parti à la fois du chiffrement et de la déduplication, votre solution de sauvegarde doit prendre en charge le chiffrement du support de stockage lui-même. Dans ce cas, pendant la restauration, les données devront être décryptées de manière transparente par le système de stockage à l'aide d'une clé de cryptage spécifique au stockage. Si le support de stockage est volé ou qu’une personne non autorisée essaye d’y accéder, le stockage ne pourra pas être décrypté sans accès au système de stockage.
Quand utiliser la déduplication ?
La déduplication a de bien meilleurs résultats lorsque le ratio de déduplication a la valeur la plus faible. Voici la formule de calcul du taux de déduplication :
Taux de déduplication = Pourcentage de données unique + (1 - Pourcentage de données unique) / Nombre de machines
Cela signifie que:
- La déduplication est plus efficace dans les environnements où il y a beaucoup de données en double sur chaque machine.
- La déduplication est plus efficace dans les environnements où vous aurez besoin de sauvegarder un grand nombre de machines/machines virtuelles/applications similaires.
De plus, la déduplication peut être utile dans d'autres scénarios, par exemple lorsque vous essayez d'optimiser votre réseau étendu (WAN).
Examinons quelques cas d'utilisation typiques.
Cas d'utilisation 1: un grand environnement avec des machines similaires
Environnement
Une centaine de postes de travail similaires doivent être sauvegardés. Les postes de travail ont d'abord été déployés à l'aide d'une solution de déploiement de système d'image disque.
Efficacité de la déduplication
Les postes de travail ont été déployés à partir d'une seule image, de sorte que le système d'exploitation et les applications génériques qui s'exécutent sur toutes les machines sont identiques. Par conséquent, il y a beaucoup de doublons. La déduplication sera d'autant plus efficace qu'il y a un grand nombre de postes de travail.
Conclusion
La déduplication est très efficace dans ce scénario car elle minimise la capacité de stockage et économise les coûts de stockage.
Cas d'utilisation 2 : optimisation du réseau étendu (WAN)
Environnement
Quarante postes de travail similaires au siège de l’entreprise doivent être sauvegardés dans un lieu distant.
Efficacité de la déduplication
Nous ne savons pas si les postes de travail ont été déployés à partir d'une seule image. Cependant, des systèmes d'exploitation similaires possèdent souvent de nombreux fichiers similaires. Supposons que 50 pour cent des données sur chaque PC est unique, ce qui est encore assez bon pour la déduplication:
Taux de déduplication = 50% + (100% - 50%) / 40 = 51,25%
L'économie approximative de stockage et de trafic réseau est de 48,75 % (100 % - 51,25 %), ce qui signifie que la déduplication réduit ces besoins de près de moitié. Comme les systèmes sont sauvegardés sur un site distant, la connexion WAN peut être relativement lente. Réduire de moitié le trafic est un avantage considérable.
Conclusion
La déduplication est une solution efficace dans ce cas car elle optimise le réseau étendu WAN.
Cas d'utilisation 3: des serveurs d'applications essentielles à l'entreprise
Environnement
Cinq serveurs d'applications, tous avec des applications différentes, doivent être sauvegardés. La quantité totale de données est de 20 To.
Efficacité de la déduplication
Les serveurs d'applications hébergent d'énormes quantités de données et différentes applications. Cela signifie qu'il y aura très peu de doublons, voire pas du tout. De plus, la quantité totale de données à sauvegarder et à traiter est très élevée.
Dans ce cas, le système de stockage indexe de grandes quantités de données, mais peu de bénéfices seront réalisés parce qu'il n'y a pas de doublons. Au pire, un seul système de stockage peut ne pas être en mesure de traiter toutes les sauvegardes en une seule journée.
Conclusion
La déduplication n'est pas efficace dans ce cas. La sauvegarde sur un stockage réseau (NAS) simple et de grande capacité est une meilleure solution.
La déduplication en résumé
La technologie de déduplication de sauvegarde aide à réduire les coûts de stockage et l'utilisation de la bande passante du réseau en éliminant les blocs de données en double lorsque vous sauvegardez et transférez des données.
La déduplication vous permettra de :
- Réduire l'utilisation de l'espace de stockage en ne stockant que des données uniques
- Éviter d’avoir besoin d'investir dans du matériel spécifique à la déduplication de données
- Réduire la charge réseau car moins de données seront transférées, ce qui laisse plus de bande passante pour vos tâches de production
Souvenez-vous cependant que le stockage dédupliqué peut nécessiter plus de ressources informatiques telles que la RAM et / ou le processeur. Dans certains cas d'utilisation (comme décrit ci-dessus ), le stockage traditionnel non dédupliqué peut être plus rentable que le stockage dédupliqué. Vous devriez toujours analyser vos besoins et votre infrastructure avant de mettre en place la déduplication.
À propos d'Acronis
Entreprise suisse fondée à Singapour en 2003, Acronis possède 15 bureaux dans le monde et des collaborateurs dans plus de 60 pays. Acronis Cyber Platform est disponible en 26 langues et dans 150 pays. Elle est utilisée par plus de 21,000 fournisseurs de services pour protéger plus de 750,000 entreprises.



