One of the things I consistently hear as I talk with clients about Disaster Recovery, is that it’s complicated. This whether the client has invested heavily in DR or not. In many cases people might have made substantial investments in technology and duplicate infrastructure and have some highly skilled people on the team – yet they still have questionable levels of confidence in their systems – and this causes them to loose sleep at night.
At the end of the day the IT folks know that its their jobs that are on the line in a disaster and that when systems go down, they will be working 24 hours a day trying to rebuild things. This also leads to the comment I hear from time to time along the lines of “My DR plan is to keep my resume polished.” or one I heard recently “I might look like I am in there rebuilding systems, but in reality I will be applying for new jobs.”
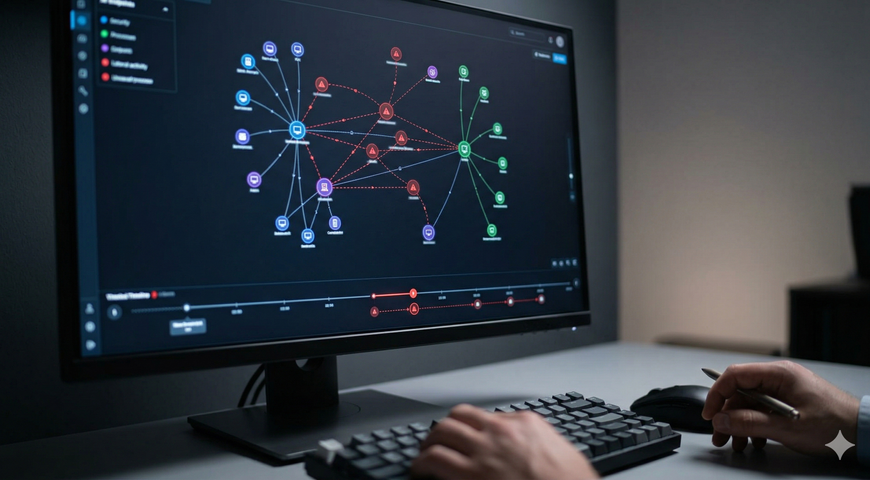
All this we see as a positive at nScaled. As a software company it’s our mission to make things easier, cheaper, more automated, and very important – easy to test. Testing is really important to us because as a service provider we will be on the end of the line when that disaster strikes. If its a regional event, we might have multiple clients to support through the failover process at the same time. The only way to succeed with this is to automate through testing ahead of time. At the end of the day we want our clients to have a ‘DR run book’ which they test twice per year to refine and validate the setup. Today we have partially succeeded with this. But we want to go further. Here are some examples of where we have succeeded:
- One button recovery of failed hosts
This might sound like a small thing but it is not. The process of taking a disk based image of an active server, and converting it into a running VM in a different location on-demand such that people can log into it and get right back to work is not trivial. Yet we have this process down to 10 minutes or so and to initiate the process is a single click in Cloud Console.
Some examples of where we are working to improve at the moment:
- Better monitoring of replications – in a couple of weeks, clients will be notified when things stop working
- Automated testing – its hard to test a system fully as we do not have log-in rights to client servers, but we can at least check that they boot and the log-in screen appears. This will be set up to run on a random schedule and provide clients with statistical reports of the health of their DR
- Automated port control in Cloud Console – so that you can redirect email traffic with a mouse click
- Clever manipulation of Active Directory – I wont go into details on this today, but it’s an important part of the testing process
About Acronis
A Swiss company founded in Singapore in 2003, Acronis has 15 offices worldwide and employees in 60+ countries. Acronis Cyber Platform is available in 26 languages in 150 countries and is used by over 21,000 service providers to protect over 750,000 businesses.