
Switching over to a microservice architecture requires reviewing approaches to development, testing, support, and design, in other words, to all aspects of the software component life cycle. In this post, we’ll share the practices that Acronis architects use to develop the best API components. This will include setting the objective and analyzing solutions to achieve it. Some people may view this post as “authoritative”, while others will wonder why they overlooked the super-solution X, but we hope you’ll find it interesting and useful.
In this post we will share details on the path we followed to define the relationships between microservices. This includes the conclusions we reached, and we would like to hear whether other architects agree with us.Microservices are the building blocks that developers use to create modern applications. Every microservice interacts with the outside world via an API. Typically, microservices are developed by separate teams that are sometimes geographically dispersed. This means their public interfaces must stay intact, and be consistent, for their work to be effective. In large organizations with hundreds of services, there needs to be an annotation for every individual component to define input data and describe the results of the work it performs in sufficient detail. If you work with HTTP REST, there are two widespread annotation formats to help do this: RAML and Open API Specification (aka Swagger). However, the issues we’re examining today are not linked to any specific protocol. That’s why what is mentioned below will even be relevant to gRPC.
Background
Acronis was founded in 2003 and over that time, its products and code base have evolved significantly. Like all companies at that time we our first products were complicated desktop applications, fast forward to today and our solutions are based on enterprise models with centralized management consoles, access rights differentiation, and audit trails. Our current initiatives are centered around transforming an enterprise application into an open platform in which the experience we gained is used to integrate external services.
If our APIs held significance before, they have now become vital. Most importantly, our processes to support these APIs has matured greatly.
Main issues
Everyone seems familiar with the problems involved in building API. We’ll describe them below as headaches for a hypothetical programmer, John, and his hypothetical manager, Jack. All the names are fictitious, but any coincidences are not purely accidental :)
1. Descriptions have grown obsolete
Let’s say John, a programmer, is developing component A, which uses API of component B. The latter has an annotation, but it is invalid. John has to go through someone else’s code, look for people, ask questions. Deadlines are closing in, and his manager, Jack, will have to deal with moving them.
2. The API is inconsistent
John has finished his task, and is focusing on the next one, which concerns the work done by component С. But the people who developed B and the people who developed C have different notions about what makes things wonderful, and so the same exact things in the API are set up differently. Once again, John has to deal with the code, and Jack is yet again impacted by unmet deadlines.
3. The API is not documented
Jack decides to publish the API of component A so that the integrators can perform miraculous integrations. But it turned out that the API documentation is not complete or is not concrete about some case. The integrators run into problems, the technical support department is overworked, Jack is overwhelmed with urgent tasks, and his programmer, John, feels it will be his turn soon.
4. The API is incompatible with the old version
The integrations have been put into place, and all the fires have been put out. But all of a sudden John decides the API for his component is far from perfect, and immerses himself in tweaking it. Naturally, when that happens, backward compatibility gets eroded, and all the integrations fall apart at the seams. This situation causes the integrators to waste time and the development company to lose money.
Treatment options
All these problems arise when the programmers don’t have a good idea about a REST API, or when that idea is fragmented. Very few developers actually have experience of working with REST. And that’s why the main scope of “treatment” methods is geared toward raising awareness. When every developer starts to have a faint glimmer of what the right API is, and that vision is coordinated with other developers, architects, and documenters, then the API becomes ideal. The process for how this vision is formed requires efforts and dedicated resources; we’ll talk about these now.
Headache 1. The annotation does not correspond to the implementation
The annotation could be different from the actual condition of the service, and not just because it’s an API from “the dark ages” that no one can find time for. This could also be an API from a bright future that has not arrived yet.The reason these kinds of conditions arise is a lack of understanding about why annotations are necessary. Unless the architects impose a reign of terror, developers tend to consider an annotation to be an internal auxiliary tool, and believe that no one from the outside will ever use it.
This headache can be cured by doing the following:
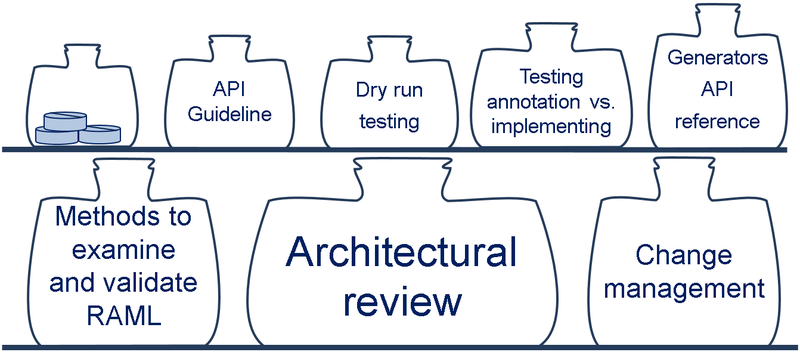
- An architectural review. This is a very useful thing for companies of any size where there is at least one programmer that “knows what’s right”. When a service is changed, the architect, or whoever is responsible, needs to keep track of the annotation status, and remind the programmers that not only the service, but its description, needs to be updated. Side effect: a bottleneck embodied in the architect.
- Generating a code from the annotations. This is often called the API-first approach. This means you make the initial annotation and then generate the primary code (there are many tools for this, such as go-swagger), and then you fill the service with business logic. This arrangement prevents discrepancies. It works well when the area for the tasks fulfilled by the service has precise boundaries.
- Testing the annotation versus the implementation. To do this, we generate a client from the (RAML/swagger) annotation that can bombard the service with queries. If the responses match the annotation, and the service itself does not crash, then everything is fine.
Testing the annotation versus the implementation
Let’s look at testing in more detail. Something similar to a completely automatic process for generating queries represents a complicated objective. Using data from the API annotations, discrete queries can be created. However, any API entails a degree of dependence, for example, before calling GET /clients/{cliend_id}, this object must first be created, and then an id obtained for it. Sometimes, that degree of dependence is less obvious: creating object X requires transferring an identifier for the associated object Y when it does not mean subcollection. Neither RAML nor Swagger allow these kinds of dependencies to be described in a form that is apparent. That’s why there are several potential approaches:
- Persuade the developers to release formal comments on the annotation that indicates the dependencies.
- Ask developers for a description of the expected sequencing (there is a fairly large number of ways to describe queries using YAML, a dedicated DSL, or via a nice GUI, as the now abandoned apigee did).
- Obtain real data REST requests tracking (for example, by using OpenResty to log all queries and responses from the server).
- Derive the dependency from the annotation using (nearly) artificial intelligence (for example, RESTler).
In any case, the objective for testing turns out to be quite labor-intensive.
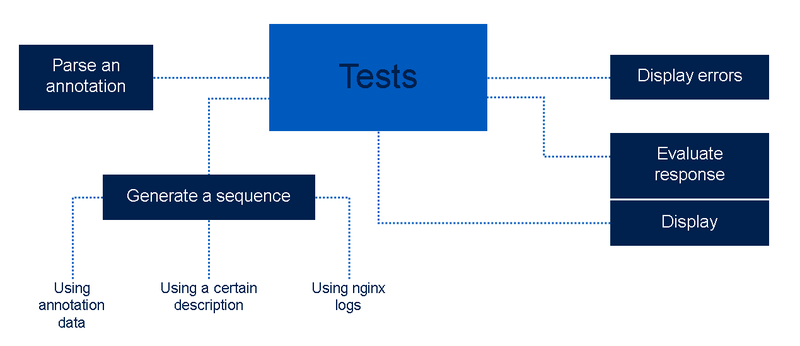
We have now arrived at the point where we have manually-prepared testing sequences. No matter what, the developers need to write the tests so that we can provide them with a convenient tool that can potentially uncover a couple of additional bugs.
Our utility software uses this kind of YAML to describe the sequencing for queries:

The braces contain the variables substituted during the testing. The variable address is conveyed as a CLI parameter, while a random variable generates an arbitrary line. The response-to-var field presents the most interest: it contains the variable that will be written in JSON with the server’s response. This means an id for the created object will be obtained in the last line with the help of task.id.
Headache 2. The API is inconsistent
What does inconsistency mean? We won’t give a formal definition; instead, we will simply state: it’s an internal contradiction. For example, in programmer John’s initial project, data had to be aggregated from the reports given at some conference, and the API provides the ability to filter data by year. When the project was almost done, the manager Jack came up to John and asked him to add a statistic for the speakers to the analysis, and to create the new “GET speakers” method so that it also filters by year. After a couple of hours, John refines the code, but during the testing process it turns out that the method doesn’t work. The reason being is that in this instance “year” is a number, and in the other it represents a line. Naturally, that is immediately obvious, and requires continuous vigilance when working with the API.
Consistency for an API is when this extreme kind of focused attention is not necessary.
There are many examples of inconsistency:
- Using different formats for the exact same data. For example, the format for time, the type of identifier (number or UUID string).
- Using different syntax for filtering or pagination.
- Different authorization schemes. It’s bad enough that the differences baffle programmers, but they also have repercussions throughout the tests that are supposed to provide support for different circuit patterns.
Treatment:
- An architectural review. If there is an architecture tyrant, then they ensure consistency. Side effects: the bus factor, as well as tyranny.
- Creating an API Guideline. This is a unified standard that needs to be developed (or a ready-made one can be adopted). But the main thing is implementing it. Raising awareness, and a stick-and-carrot approach, are needed to accomplish this.
- Dry-run testing to determine that an annotation complies with an API Guideline.
Each company makes its choice about which guideline to use. And, most likely, there is no universal approach about what is needed and what is not. After all, the more provisions in a standard, the stricter you must be about control, and the more restrictions you must place on creativity. And an important thing to consider is that very few people will read a document with “only 100 pages” to the very end.
In our company, we have included the following issues in our guideline:

There are some other examples of good guidelines from Microsoft, PayPal, and Google.
Headache 3. The API is not documented
An annotation is a necessary, yet insufficient, condition to simplify working with an API. Annotations can be written in a way that doesn’t realize their full potential. This occurs when:
- There are not enough descriptions (for the parameters, headers, errors, etc.).
- There are not enough usage examples, since an example can be used not only to improve the quality of documentation (there is more context for the developer, and the ability to play around interactively with the API directly from the portal), but also of the testing (as a fuzzing-a starting point).
- There are undocumented functions.
This typically happens when the developers do not have a clear idea why annotations are necessary, when there is a lack of communication between the technical writers and the programmers, and if nobody has ever calculated just how much working with bad-quality documentation costs the company. And if they go to a programmer and pestered them after each request for support, all annotations would get filled out very quickly.
Treatment:
- Having API reference generation tools available for programmers. If developers see how the description of their API looks for coworkers and users, then they will do their best to improve the annotation. Side effects: configuring these tools requires additional helping hands.
- Fine-tuning the interaction between all involved parties: programmers, evangelists, and support personnel. Side effects: everyone must have meetings with everyone else, the processes become more difficult.
- Using tests based on an API annotation. Implementing the dry-run tests stated above in CI repositories with annotations.
At Acronis, annotations are used to generate an API reference with SDK clients and try-it sections. Along with the code samples and descriptions of use cases, they form the full range of necessary and convenient supplements for programmers. Take a look at our portal at http://developer.acronis.com.
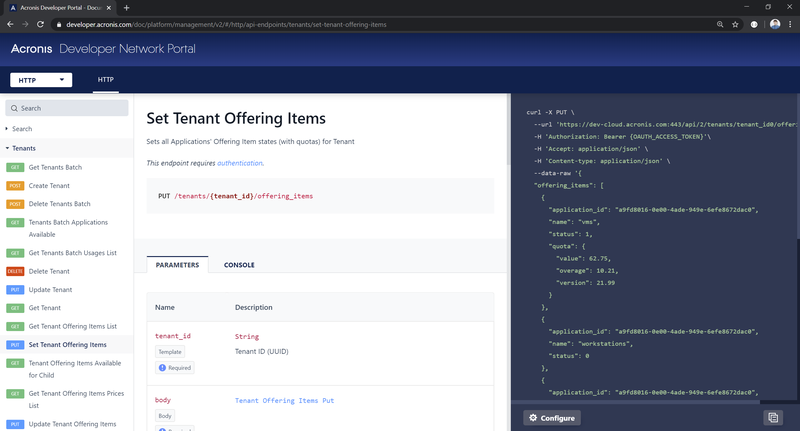
There is an entire category of tools to generate an API reference. Some companies independently develop similar instruments for their own needs. Others employ tools that are fairly simple to use and free of charge, such as Swagger Editor.
Headache 4. Problems with backward compatibility
Backward compatibility could become disrupted because of any small trifle. For example, John writes the word compatibility with a typo every single time: compatibility. This typo comes up in the code, in the comments, and in a query parameter. Noticing his mistake, John replaces this word throughout the whole project, and, without looking at it, he sends it off to production. It goes without saying that backward compatibility will be disrupted, and the service will be shut down for several hours.
How is it even possible for these events to occur? The principal reason lies in not understanding the API life cycle, which can manifest itself in both breaking integrations and unpredictable EOL (End of Life) policies, as well as in unclear API releases.
Treatment:
- An architectural review. As always, an architect’s firm hand can prevent disruptions in backward compatibility. However, their main task is to explain the cost of keeping several services, and explaining the options for introducing changes without the existing API breaking down.
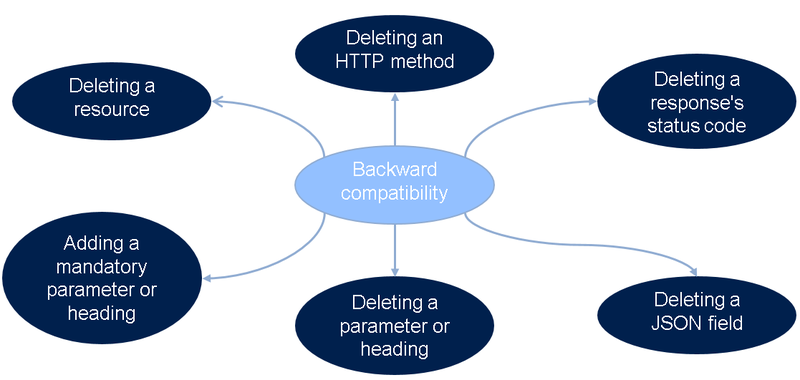
- Checking for backward compatibility. If the API annotation contains an updated description, then it is possible to check to see whether backward compatibility is disrupted at the CI stage.
- Timely updating documentation. The API reference and description need to be updated at the same time the service code changes. To do this, you can even have standardized checklists, adjusting notifications about changes, or train superpowers to generate everything from anything…It’s important! The documentation management teams need to be kept posted about all planned changes so they can plan resource allocation to update documentation and write upgrade guides. An upgrade guide that is tried-and-true is a regrettably indispensable attribute of any renaming activity that you can mastermind in an API.
Change Management
The rules describing the activity linked to an API life cycle are called change management policies.

If you have two versions of an annotation, “current” and “new”, checking for backward compatibility is easy: after parsing both annotations, required fields must be checked to make sure they’re present.
We’ve written a special-purpose tool that can compare all the parameters that are critical for backward compatibility in the CI. For example, if changes occur in the body of the response to the query GET /healthcheck, then the following type of message is delivered:

Conclusion
Every architect dreams of eliminating problems involved in their APIs. Every manager dreams of not hearing about any problems with the APIs. :) There are many medicines, but each comes with its own price, and has its own side effects. We’ve shared our own options for treating the childhood illnesses APIs suffer from, which later evolve into more serious diseases. The conclusions that can be drawn from our article are “authoritative”: the problems with APIs begin in people’s minds, and training them in the best practices is the main guarantee of success. Everything else is just a technicality. What kinds of problems have you come across, and which methods has your organization embraced to help resolve them?
About Acronis
A Swiss company founded in Singapore in 2003, Acronis has 15 offices worldwide and employees in 50+ countries. Acronis Cyber Protect Cloud is available in 26 languages in 150 countries and is used by over 21,000 service providers to protect over 750,000 businesses.



