
Die Backup-Deduplizierungstechnologie trägt dazu bei, die Speicherkosten und die Auslastung der Netzwerkbandbreite zu reduzieren, indem doppelte Datenblöcke beim Sichern und Übertragen von Daten eliminiert werden.
Deduplizierung hilft Ihnen dabei durch:
⦁ Verringerung des Speicherplatzbedarfs durch Speicherung nur eindeutiger Daten
⦁ Sie müssen nicht mehr in spezielle Hardware für die Datendeduplizierung investieren.
⦁ Geringere Netzwerkbelastung, da weniger Daten übertragen werden und mehr Bandbreite für Ihre Produktionsaufgaben zur Verfügung steht
Bedenken Sie jedoch, dass deduplizierter Speicher unter Umständen mehr Rechenressourcen wie RAM und/oder CPU erfordert. In einigen Anwendungsfällen kann traditioneller nicht-duplizierter Speicher kostengünstiger sein als deduplizierter. Bevor Sie Deduplizierung implementieren, sollten Sie immer Ihren Bedarf und Ihre Infrastruktur analysieren.
Herausforderungen bei der Backup-Speicherung
Wir leben im Zeitalter von Big Data.
Im Jahr 1990 hatte die Festplatte eines PCs eine Größe von 10 Megabyte. Heute sind Festplatten mit mehreren Terabyte die Norm. Alle 10 Minuten schafft die Menschheit so viel Datenvolumen, wie seit Beginn der Zivilisation bis zum Jahr 2000 entstanden ist.
Sie müssen all diese Daten schützen und sichern. Andernfalls kann Ihr Unternehmen Geld, Ansehen und Zeit verlieren - Ihr ganzes Geschäft kann sogar zum Erliegen kommen.

Allerdings geben 75 Prozent der von Acronis und IDC (International Data Corporation) befragten kleinen und mittleren Unternehmen (KMU) zu, dass ihre Daten nicht vollständig geschützt sind. Die "schiere Datenmenge" wurde als einer der Hauptgründe dafür genannt.
Nehmen wir zum Beispiel ein Unternehmen mit 400 Mitarbeitern, die Desktops und Laptops verwenden. Ein durchschnittlicher Laptop kann zwischen 50 und einigen hundert Gigabyte an Daten auf der Festplatte speichern. PCs enthalten zwischen 20 und 150 TB (Terabyte) an Daten. Bei einem Komprimierungsverhältnis von 2:1 muss der Backup-Administrator zwischen 10 und 75 TB für jedes vollständige Backup bereitstellen und darüber hinaus noch mehr Platz für inkrementelle und differenzielle Backups haben. Möglicherweise muss dieses Unternehmen allein für PC-Backups ein Petabyte Speicherplatz anschaffen.
Nehmen wir an, dieses Unternehmen investiert in teuren Speicher für seine PC-Backups. Die nächste, noch größere Herausforderung besteht darin, die PCs auf diesem Speicher zu sichern. Ein 100 Mbit (Megabit)-Netzwerk kann nur 10 Megabyte Daten pro Sekunde übertragen. Bei dieser Geschwindigkeit dauert eine vollständige Datensicherung zwei bis drei Wochen, um 10 bis 75 TB Daten über ein 100-Mbit-Netz zu übertragen.
Auf jedem Desktop befinden sich jedoch dasselbe Windows-Betriebssystem, dieselben Anwendungen und oft zahlreiche Kopien derselben Daten. Das mehrfache Speichern und Übertragen der gleichen Daten auf den gleichen Speicherplatz ist eine Verschwendung von Zeit und Ressourcen. Wenn eine Backup-Lösung nur einmalige Daten überträgt und speichert, kann das Unternehmen seine Speicherkapazität und seine Netzwerkanforderungen um das bis zu 50-fache reduzieren! Mit Deduplizierung kann Ihr Unternehmen diese Einsparungen realisieren.
Was ist Backup-Deduplizierung?
Die Backup-Deduplizierung minimiert den Speicherplatz, indem sie Datenwiederholungen erkennt und die identischen Daten nur einmal speichert. Die Deduplizierung verringert auch die Netzwerklast, da Duplikate von Daten, die zuvor gesichert wurden, gar nicht erst über das Netzwerk zum Speicher übertragen werden.
Wenn Sie die Deduplizierung aktivieren, dedupliziert Ihre Backup-Lösung die Backups und speichert sie in einem verwalteten Speicher. Ein Speicherort, an dem die Deduplizierung aktiviert ist, wird als Deduplizierungsspeicher bezeichnet.
Die Deduplizierung kann auf Datei-, Unterdatei- (Teile von Dateien) oder Blockebene erfolgen und funktioniert in der Regel mit allen von Ihrer Backup-Lösung unterstützten Betriebssystemen.
Die Deduplizierung bringt maximale Ergebnisse, wenn Sie sie erstellen:
⦁ Vollständige Backups ähnlicher Daten aus verschiedenen Quellen, z. B. Betriebssysteme (OS), virtuelle Maschinen (VMs) und Anwendungen, die aus einem Standard-Image bereitgestellt werden
⦁ Vollständige Backups von Systemen, die Sie zuvor auf demselben deduplizierenden Speicher gesichert haben
⦁ Inkrementelle Backups ähnlicher Daten aus verschiedenen Quellen, z. B. wenn Sie Betriebssystem-Updates auf mehreren Systemen verteilen und ein ⦁ inkrementelles Backup durchführen
⦁ Inkrementelle Backups, bei denen sich die Daten nicht ändern, aber der Speicherort der Daten sich ändert, z. B. wenn Daten, wie eine Datei, über das Netzwerk oder innerhalb eines Systems zirkulieren und an einem neuen Ort erscheinen
Wie funktioniert die Backup-Deduplizierung?
Bei der Deduplizierung werden die Sicherungsdaten in Blöcke aufgeteilt. Die Einzigartigkeit jedes Blocks wird durch eine spezielle Datenbank überprüft, die die Prüfsummen aller gespeicherten Blöcke verfolgt. Einzigartige Blöcke werden an den Speicher gesendet und Duplikate werden übersprungen.
Wenn zum Beispiel 10 virtuelle Maschinen auf dem deduplizierten Speicher gesichert werden und derselbe Block in fünf von ihnen gefunden wird, wird nur eine Kopie dieses Blocks gesendet und gespeichert.
Dieser Algorithmus zum Überspringen doppelter Blöcke spart Speicherplatz und minimiert den Netzwerkverkehr.
Deduplizierung an der Quelle
Bei der Durchführung einer Sicherung auf einem deduplizierenden Speicher berechnet die Sicherungslösung einen Fingerabdruck oder eine Prüfsumme jedes Datenblocks. Dieser Fingerabdruck oder diese Prüfsumme wird oft als Hash-Wert bezeichnet.
Ihre Backup-Lösung kann Blöcke mit fester oder variabler Größe unterstützen. Die Deduplizierung von Blöcken mit fester Größe hat sich als ineffektiv erwiesen - bei kleinen Blöcken verbraucht sie viel RAM und CPU, und bei großen Blöcken ist die Deduplizierungsrate viel geringer.
Die meisten fortschrittlichen modernen Backup-Lösungen bieten eine Block-Deduplizierung mit variabler Größe und passen die Blockgrößen an, um die Deduplizierungsrate zu maximieren und gleichzeitig die RAM- und CPU-Auslastung zu reduzieren.
Bevor der Datenblock an das Speichersystem gesendet wird, fragt die Backup-Lösung das Speichersystem ab, um festzustellen, ob der Hash-Wert des Blocks dort bereits gespeichert ist. Ist dies der Fall, sendet die Lösung nur den Hash-Wert; andernfalls sendet sie den Block selbst.
Einige Daten, z. B. verschlüsselte Dateien oder Festplattenblöcke mit einer nicht standardisierten Größe, können nicht dedupliziert werden. In diesen Fällen würde die Lösung diese Daten immer auf den Speicher übertragen, ohne die Hash-Werte zu berechnen.
Deduplizierung bei Target
Nachdem ein Backup auf einen deduplizierenden Speicher abgeschlossen ist, führt das Speichersystem eine speicherseitige Deduplizierung durch. Normalerweise läuft dieser Prozess wie folgt ab:
1. Die Datenblöcke werden von der Sicherungsdatei in eine spezielle Datei - den Deduplizierungsdatenspeicher - innerhalb des Speichers verschoben. Doppelte Blöcke werden nur einmal gespeichert.
2. Hash-Werte und Links zu Datenblöcken werden in der Deduplizierungsdatenbank gespeichert, so dass die Daten leicht wieder zusammengesetzt (rehydriert) werden können.
Infolgedessen enthält der Datenspeicher eine Reihe von eindeutigen Datenblöcken. Jeder Block hat eine oder mehrere Referenzen aus den Backups. Die Referenzen werden in der Deduplizierungsdatenbank gespeichert.
Die folgende Abbildung veranschaulicht das Ergebnis der Deduplizierung am Zielort
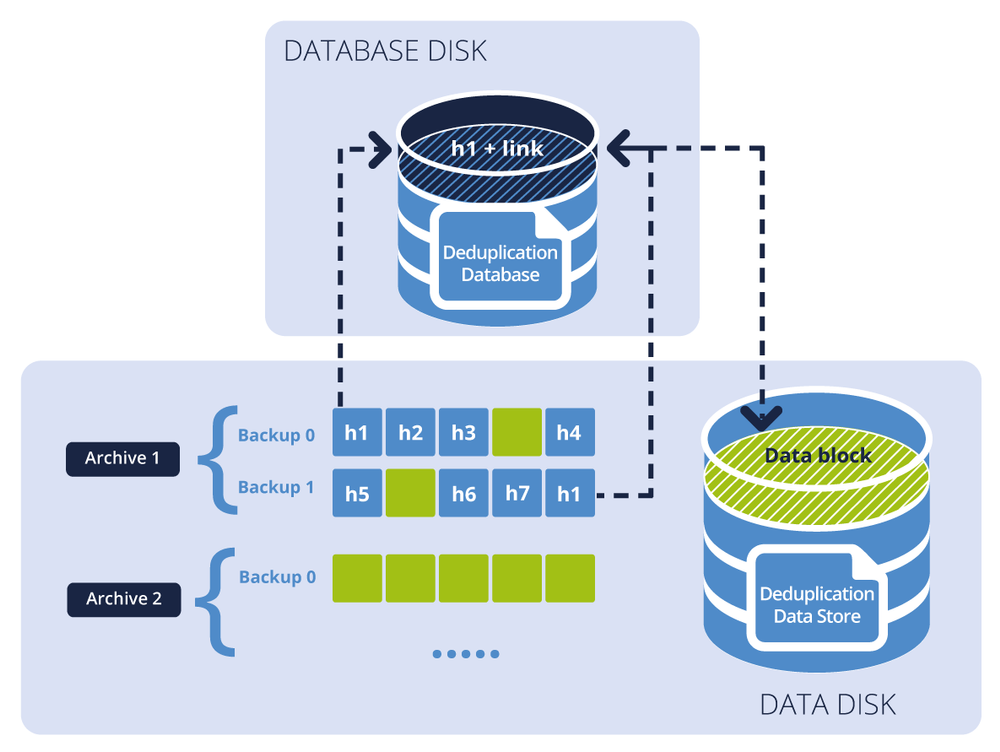
Das Diagramm zeigt zwei Sicherungsarchive. Jedes hat einen eigenen Satz von Sicherungen. In Archiv 1 enthalten die Blöcke h1 bis h7 - gekennzeichnet durch blaue Blöcke - die in den Sicherungsdateien gespeicherten Hash-Werte. Die grünen Blöcke sind die Datenblöcke, die nicht dedupliziert werden können. Archiv 2 enthält nur Datenblöcke (grün) und ist verschlüsselt. Folglich enthält die Deduplizierungsdatenbank Hash-Werte von Blöcken, die dedupliziert werden können, und der Deduplizierungsdatenspeicher enthält Datenblöcke sowohl aus Archiv 1 als auch aus Archiv 2.
Wiederherstellung
Bei der Wiederherstellung fordert der Datensicherungsagent die Daten aus dem Speicher an. Das Speichersystem liest die Sicherungsdaten aus dem Speicher, und wenn ein Block im Deduplizierungsdatenspeicher referenziert wird, liest das Speichersystem die Daten aus diesem. Für einen Agenten ist der Wiederherstellungsprozess transparent und unabhängig von der Deduplizierung.
Löschen von verwaisten Datenblöcken
Nachdem eine oder mehrere Sicherungen aus dem Speicher gelöscht wurden - entweder manuell oder durch Aufbewahrungsregeln - kann der Datenspeicher Blöcke enthalten, die von keiner Sicherung mehr referenziert werden. Diese verwaisten Blöcke werden durch eine spezielle, vom Speichersystem durchgeführte, geplante Aufgabe gelöscht.
Das funktioniert folgendermaßen: Zunächst durchsucht das Speichersystem alle Backups im Speicher und markiert alle referenzierten Blöcke als verwendet (der entsprechende Hash wird in der Deduplizierungsdatenbank als verwendet markiert). Anschließend löscht das Speichersystem alle ungenutzten Blöcke.
Dieser Vorgang kann zusätzliche Systemressourcen erfordern. Deshalb wird diese Aufgabe in der Regel nur ausgeführt, wenn sich eine ausreichende Menge an Daten in Ihrem Speicher angesammelt hat.
Komprimierung und Verschlüsselung
Der Datensicherungsagent komprimiert normalerweise die gesicherten Daten, bevor er sie an den Server sendet. Vor der Komprimierung werden Hash-Werte für jeden Datenblock berechnet. Das bedeutet, dass zwei gleiche Blöcke, die mit unterschiedlichen Komprimierungsgraden komprimiert wurden, dennoch als Duplikate erkannt werden.
Auf der Quellseite verschlüsselte Backups werden aus Sicherheitsgründen nicht dedupliziert.
Um sowohl Verschlüsselung als auch Deduplizierung zu nutzen, sollte Ihre Backup-Lösung die Verschlüsselung des verwalteten Speichers selbst unterstützen. In diesem Fall würden die Daten bei der Wiederherstellung vom Speichersystem mit einem speicherspezifischen Verschlüsselungsschlüssel transparent entschlüsselt. Wenn das Speichermedium gestohlen wird oder ein Unbefugter darauf zugreift, kann der Speicher ohne Zugriff auf das Speichersystem nicht entschlüsselt werden.
Wann sollten Sie Deduplizierung verwenden?
Die Deduplizierung hat die größten Auswirkungen, wenn die Deduplizierungsquote den niedrigsten Wert hat. Hier ist die Formel für die Berechnung der Deduplizierungsquote:
Deduplizierungsverhältnis = Prozentsatz einzigartiger Daten + (1 - Prozentsatz einzigartiger Daten) / Anzahl der Rechner
Dies bedeutet, dass:
1. Die Deduplizierung am effektivsten in Umgebungen ist, in denen es viele doppelte Daten auf jedem Rechner gibt.
2. Deduplizierung am effektivsten in Umgebungen ist, in denen Sie viele ähnliche Maschinen/virtuelle Maschinen/Anwendungen sichern müssen.
Darüber hinaus kann die Deduplizierung auch in anderen Szenarien hilfreich sein, z. B. wenn Sie versuchen, Ihr Wide Area Network (WAN) zu optimieren.
Schauen wir uns einige typische Anwendungsfälle an.
Anwendungsfall 1: Große Umgebung mit ähnlichen Maschinen
Umgebung
Hundert ähnliche Arbeitsstationen müssen gesichert werden. Die Workstations wurden ursprünglich mit einer Disk-Imaging-System-Bereitstellungslösung bereitgestellt.
Deduplizierungseffekt
Die Workstations wurden von einem einzigen Image bereitgestellt, so dass das Betriebssystem und die allgemeinen Anwendungen, die auf allen Rechnern laufen, identisch sind. Infolgedessen gibt es viele Duplikate. Die Deduplizierung ist sogar noch effektiver, weil es eine große Anzahl von Arbeitsplätzen gibt.
Schlussfolgerung
Die Deduplizierung ist in diesem Szenario sehr effektiv, da sie die Speicherkapazität minimiert und Speicherkosten spart.
Anwendungsfall 2: WAN-Optimierung
Umgebung
Vierzig ähnliche Arbeitsstationen im Hauptbüro müssen an einem entfernten Standort gesichert werden.
Deduplizierungseffekt
Wir wissen nicht, ob die Arbeitsplatzrechner aus einem einzigen Image bereitgestellt wurden. Ähnliche Betriebssystemtypen haben jedoch oft viele ähnliche Dateien. Gehen wir davon aus, dass 50 Prozent der Daten auf jedem PC einzigartig sind - das ist immer noch recht gut für die Deduplizierung:
Deduplizierungsquote = 50% + (100% - 50%) / 40 = 51,25%
Die ungefähre Einsparung an Speicherplatz und Netzwerkverkehr beträgt 48,75 % (100 % - 51,25 %), was bedeutet, dass die Deduplizierung diese Anforderungen fast halbiert. Da die Systeme an einem entfernten Standort gesichert werden, kann die WAN-Verbindung relativ langsam sein. Die Halbierung des Datenverkehrs ist ein großer Vorteil.
Schlussfolgerung
Die Deduplizierung ist eine effektive Lösung für diesen Fall, da sie das WAN-Netzwerk optimiert.
Anwendungsfall 3: Geschäftskritische Anwendungsserver
Umgebung
Fünf Anwendungsserver, alle mit unterschiedlichen Anwendungen, müssen gesichert werden. Die Gesamtmenge der Daten beträgt 20 TB.
Wirksamkeit der Deduplizierung
Anwendungsserver hosten riesige Datenmengen und verschiedene Anwendungen. Das bedeutet, dass es, wenn überhaupt, nur sehr wenige Duplikate gibt. Außerdem ist die Gesamtmenge der zu sichernden und zu verarbeitenden Daten sehr hoch.
In diesem Fall indiziert das Speichersystem große Datenmengen, aber der Nutzen ist gering, da es keine Duplikate gibt. Im schlimmsten Fall ist ein einziges Speichersystem nicht in der Lage, alle Backups an einem Tag zu verarbeiten.
Schlussfolgerung
Die Deduplizierung ist in diesem Fall nicht effektiv. Die Sicherung auf einem einfachen Netzwerkspeicher (NAS) mit hoher Kapazität ist eine bessere Lösung.
Deduplizierung im Überblick
Die Backup-Deduplizierungstechnologie trägt dazu bei, die Speicherkosten und die Auslastung der Netzwerkbandbreite zu reduzieren, indem doppelte Datenblöcke beim Sichern und Übertragen von Daten eliminiert werden.
Deduplizierung hilft Ihnen dabei durch:
1. Verringerung des Speicherplatzbedarfs durch Speicherung nur eindeutiger Daten
2. Sie müssen nicht mehr in spezielle Hardware für die Datendeduplizierung investieren.
3. Geringere Netzwerkbelastung, da weniger Daten übertragen werden und mehr Bandbreite für Ihre Produktionsaufgaben zur Verfügung steht
Bedenken Sie jedoch, dass deduplizierter Speicher mehr Rechenressourcen, wie RAM und/oder CPU, erfordern kann. In einigen Anwendungsfällen (wie oben beschrieben) kann herkömmlicher nicht-duplizierter Speicher kostengünstiger sein als deduplizierter. Bevor Sie Deduplizierung implementieren, sollten Sie immer Ihren Bedarf und Ihre Infrastruktur analysieren.
Über Acronis
Acronis ist ein Schweizer Unternehmen, das 2003 in Singapur gegründet wurde. Das Unternehmen hat weltweit 15 Standorte und beschäftigt Mitarbeiter:innen in über 50 Ländern. Acronis Cyber Protect Cloud ist in 26 Sprachen in 150 Ländern verfügbar und wird von mehr als 21,000 Service Providern zum Schutz von über 750,000 Unternehmen eingesetzt.



