Backup deduplication technology helps reduce storage costs and network bandwidth utilization by eliminating duplicate data blocks when you back up and transfer data.
Deduplication helps you to:
- Reduce storage space usage by storing only unique data
- Eliminate the need to invest in data deduplication-specific hardware
- Reduce network load because less data is transferred, leaving more bandwidth for your production tasks
Remember, however, that deduplicated storage may require more computing resources, such as RAM and/or CPU. In some use cases traditional non-deduplicated storage may be more cost-effective than deduplicated. You should always analyze your needs and infrastructure before implementing deduplication.
Backup Storage Challenges
We are living in the era of big data.
In 1990, the hard disk of a personal computer was 10 megabytes. Now, multi-terabyte disks are the norm. Every 10 minutes, humanity creates as much data volume as was created from the dawn of civilization until the year 2000.
You must protect and back up all this data. Otherwise your company can lose money, reputation, time — your entire business can even shut down.

However, 75 percent of small-to medium-sized businesses (SMBs) surveyed by Acronis and IDC (International Data Corporation) admit that their data is not fully protected. The “sheer volume of data” was given as one of the primary reasons why.
For example, let’s look at a company with 400 employees who use desktops and laptops. An average laptop can hold from 50 to a few hundred gigabytes of data on the hard disk. PCs contain from 20 to 150TB (terabytes) of data. With a 2:1 compression ratio, the backup administrator needs to provision between 10 to 75TB for every full backup, plus have more space for incremental and differential backups. Eventually, this company may need to acquire as much as a one petabyte of storage for PC backups alone.
Let’s assume this company invests in expensive storage for their PC backups. The next, even bigger challenge is to back up the PCs to this storage. A 100 Mbit (megabit) network can transfer only 10 megabytes of data per second. At this rate, a full backup will take from two to three weeks to transfer 10 to 75 TB of data over a 100 Mbit network.
Yet, every desktop has the same Windows operating system, same applications, and often numerous copies of the same data. Storing and transferring the same data multiple times to the same storage is a waste of time and resources. If a backup solution transfers and stores only unique data, the company can decrease their storage capacity and network requirements by up to 50 times! With deduplication, your organization can realize these savings.
What Is Backup Deduplication?
Backup deduplication minimizes storage space by detecting data repetition and storing the identical data only once. Deduplication also reduces network load, because duplicates of data previously backed up is not even transferred over the network to storage.
When you enable deduplication, your backup solution deduplicates the backups and saves them to a managed storage. A storage location where deduplication is enabled is called a deduplicating storage.
Deduplication can operate at a file-, sub file- (pieces of files), or block-level and usually works with all operating systems supported by your backup solution.
Deduplication produces maximum results when you create:
- Full backups of similar data from different sources, such as operating systems (OS), virtual machines (VMs), and applications deployed from a standard image
- Full backups of systems that you previously backed up to the same deduplicating storage
- Incremental backups of similar data from different sources; for example, when you deploy OS updates to multiple systems and run an incremental backup
- Incremental backups where the data does not change but the location of data does change; for example, when data, such as a file, circulates over the network or within one system and appears in a new place
How Does Backup Deduplication Work?
During deduplication, the backup data is split into blocks. Each block’s uniqueness is checked through a special database, which tracks all the stored blocks’ checksums. Unique blocks are sent to the storage and duplicates are skipped.
For example, if 10 virtual machines are backed up to the deduplicated storage and the same block is found in five of them, only one copy of this block is sent and stored.
This algorithm of skipping duplicate blocks saves storage space and minimizes network traffic.
Deduplication at Source
When performing a backup to a deduplicating storage, the backup solution calculates a fingerprint or a checksum of each data block. This fingerprint or checksum is often called a hash value.
Your backup solution may support blocks of fixed size or variable size. The fixed-size block deduplication has proven to be ineffective – on small block sizes, it consumes a lot of RAM and CPU; and on large block sizes, it provides much lower deduplication ratio.
Most advanced modern backup solutions provide variable-size block deduplication, adapting the block sizes to maximize the deduplication ratio, while reducing RAM and CPU usage.
Before sending the data block to the storage, the backup solution queries the storage system to determine whether the block’s hash value is already stored there. If so, the solution sends only the hash value; otherwise, it sends the block itself.
Some data, such as encrypted files or disk blocks of a non-standard size, cannot be deduplicated. In these cases, the solution would always transfer this data to the storage without calculating the hash values.
Deduplication at Target
After a backup to a deduplicating storage is complete, the storage system performs storage-side deduplication. Usually this process works as follows:
- Data blocks are moved from the backup file to a special file — the deduplication data store — within the storage. Duplicate blocks are stored only once.
- Hash values and links to data blocks are saved to the deduplication database, so the data can be easily reassembled (rehydrated).
As a result, the data store contains a number of unique data blocks. Each block has one or more references from the backups. The references are recorded in the deduplication database.
The figure below illustrates the result of deduplication at target.
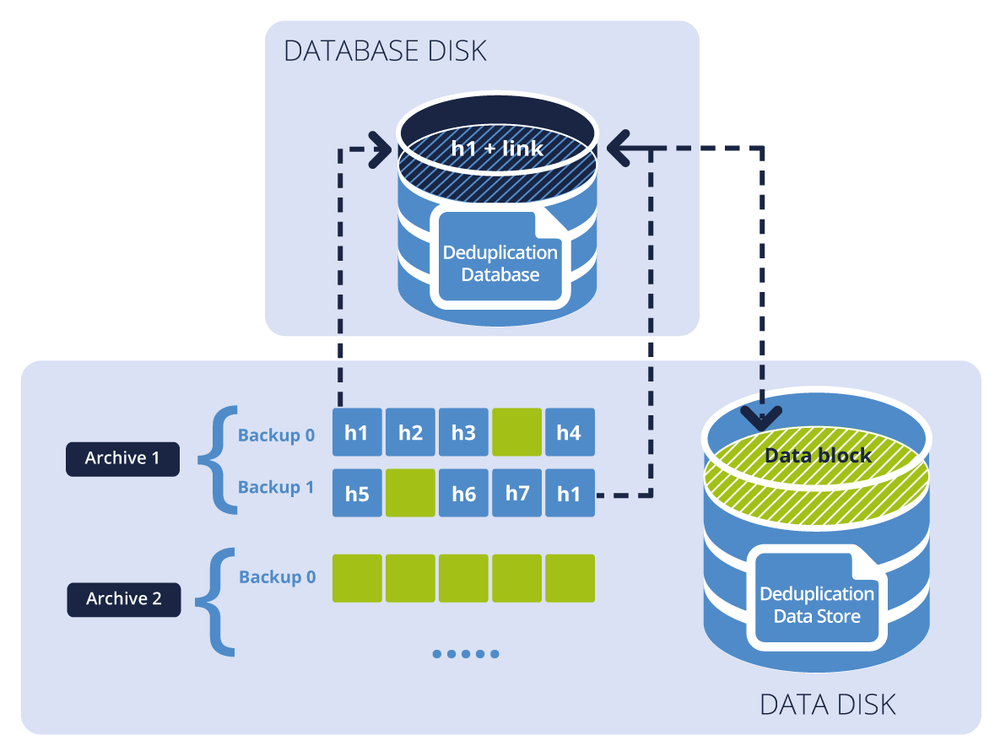
The diagram shows two backup archives. Each has a separate set of backups. In Archive 1, h1 through h7 — designated by blue blocks — contain hash values stored in the backup files. The green blocks are the data blocks that cannot be deduplicated. Archive 2 contains only data (green) blocks and is encrypted. As a result, the deduplication database contains hash values of blocks that can be deduplicated, and the deduplication data store contains data blocks from both Archive 1 and Archive 2.
Recovery
During recovery, the backup solution agent requests the data from the storage. The storage system reads backup data from the storage and if a block is referenced in the deduplication data store, the storage system reads data from it. For an agent, the recovery process is transparent and independent of the deduplication.
Deleting Orphan Data Blocks
After one or more backups are deleted from the storage — either manually or through retention rules — the data store may contain blocks, which are no longer referenced by any backup. These orphan blocks are deleted by a special scheduled task run by the storage system.
Here is how it works. First, the storage system scans through all backups in the storage and marks all referenced blocks as used (the appropriate hash is marked as used in the deduplication database). Second, the storage system deletes all the unused blocks.
This process may require additional system resources. That is why this task usually runs only when a sufficient amount of data has accumulated in your storage.
Compression and Encryption
The backup solution agent would usually compress the backed up data before sending it to the server. Hash values for each data block are calculated before compression. This means that if two equal blocks are compressed with different levels of compression, they are still recognized as duplicates.
Backups encrypted on the source side are not deduplicated for security reasons.
To leverage both encryption and deduplication, your backup solution should support encrypting the managed storage itself. In this case, during recovery, the data would be transparently decrypted by the storage system using a storage-specific encryption key. If the storage medium is stolen or accessed by an unauthorized person, the storage cannot be decrypted without access to the storage system.
When Should You Use Deduplication?
Deduplication has the greatest impact when the deduplication ratio has the lowest value. Here is the formula for the deduplication ratio calculation:
Deduplication ratio = Unique data percentage + (1 – Unique data percentage) / Number of machines
This means that:
- Deduplication is most effective in environments where there is a lot of duplicate data on each machine
- Deduplication is most effective in environments where you need to back up a lot of similar machines/virtual machines/applications
In addition, deduplication can help in other scenarios, such as when you are trying to optimize your wide area network (WAN).
Let us look at some typical use cases.
Use Case 1: Big Environment With Similar Machines
Environment
One hundred similar workstations need to be backed up. The workstations were initially deployed using a disk-imaging system deployment solution.
Deduplication effect
The workstations were deployed from a single image, so the operating system and generic applications that run on all machines are identical. As a result, there are many duplicates. Deduplication is even more effective because there are a large number of workstations.
Conclusion
Deduplication is very effective in this scenario because it minimizes storage capacity and saves storage costs.
Use Case 2: WAN Optimization
Environment
Forty similar workstations in the main office need to be backed up to a remote location.
Deduplication effect
We do not know if the workstations were deployed from a single image. However, similar types of operating systems often have many similar files. Let us assume that 50 percent of the data on each PC is unique — still quite good for deduplication:
Deduplication ratio = 50% + (100% – 50%) / 40 = 51.25%
The approximate storage and network traffic savings is 48.75 percent (100% – 51.25%), which means deduplication cut these requirements almost in half. Since the systems are backed up to a remote location, the WAN connection can be relatively slow. Halving the traffic offers a big advantage.
Conclusion
Deduplication is an effective solution for this case because it optimizes the network WAN.
Use Case 3: Business-Critical Application Servers
Environment
Five application servers, all with different applications, need to be backed up. The total amount of data is 20TB.
Deduplication effectiveness
Application servers host huge amounts of data and different applications. This means there will be very few, if any duplicates at all. Moreover, the total amount of data to be backed up and processed is very high.
In this case, the storage system indexes large amounts of data but little benefit is realized because there are no duplicates. In the worst-case scenario, a single storage system may not be able to process all the backups in one day.
Conclusion
Deduplication is not effective for this case. Backing up to a simple, high-capacity, network-attached storage (NAS) is a better solution.
Deduplication in Summary
Backup deduplication technology helps reduce storage costs and network bandwidth utilization by eliminating duplicate data blocks when you back up and transfer data.
Deduplication helps you to:
- Reduce storage space usage by storing only unique data
- Eliminate the need to invest in data deduplication-specific hardware
- Reduce network load because less data is transferred, leaving more bandwidth for your production tasks
Remember, however, that deduplicated storage may require more computing resources, such as RAM and/or CPU. In some use cases (as described above), traditional non-deduplicated storage may be more cost-effective than deduplicated. You should always analyze your needs and infrastructure before implementing deduplication.
About Acronis
A Swiss company founded in Singapore in 2003, Acronis has 15 offices worldwide and employees in 60+ countries. Acronis Cyber Platform is available in 26 languages in 150 countries and is used by over 21,000 service providers to protect over 750,000 businesses.



